
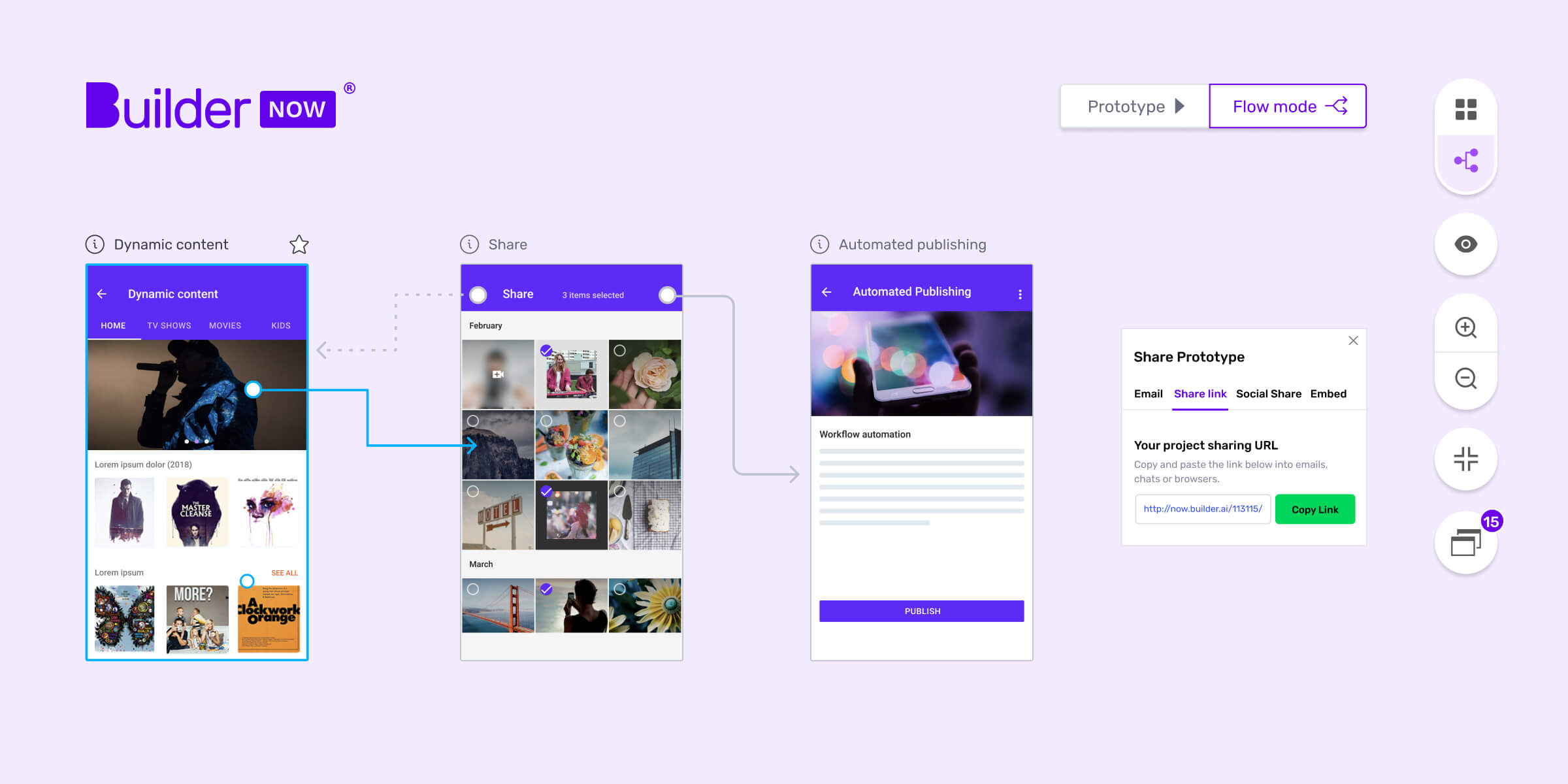
If you’re building an app it’s scary to make big time and cost commitments without being able to see how your new app will work. I’ve found prototypes are useful for both us and you (it’s much easier to make improvements before development starts). But on our first app prototyping tool, even working out the most suitable start screen for the prototype was labour intensive.
So we tried using machine learning and a link prediction model, combined with our graph database – to see if it was possible to remove human labour and offer customers logical prototypes instantly.
Automation and app development
You can create a blueprint of your app idea in Builder Studio by adding features (things like Login, Shopping Cart or Push Notifications) to a Buildcard™. It’s like adding toppings on a pizza.
Then we use automation to convert your Buildcard (initially, a set of disconnected features) into an interactive prototype. You can view these prototypes as graphs, where nodes represent features and edges show how features link to each other.
How we do it
- Predict connections between features – using a link prediction model based on machine learning.
- Work out the best start screen for each app – using a probabilistic/heuristics-based approach.
- Ensure all features can be reached from the start screen(and user journeys are complete) – using graph navigation libraries.
Want to start your app project with us?
Book a demoSpeak with one of our product experts today.
By proceeding you agree to Builder.ai’s privacy policy and terms and conditions

Why do we need automatic prototypes?
Our app building platform, Builder Studio, treats features as independent entities – we don’t consider your actual user journey and interactions between features, at this stage. Once you’ve chosen the features your idea needs, you transfer your Buildcard into our prototyping tool, Builder Now. This lets you click through a prototype of your app, visualise how it’ll work and improve your user journeys, it also gives you a flow chart of connected features, like this.
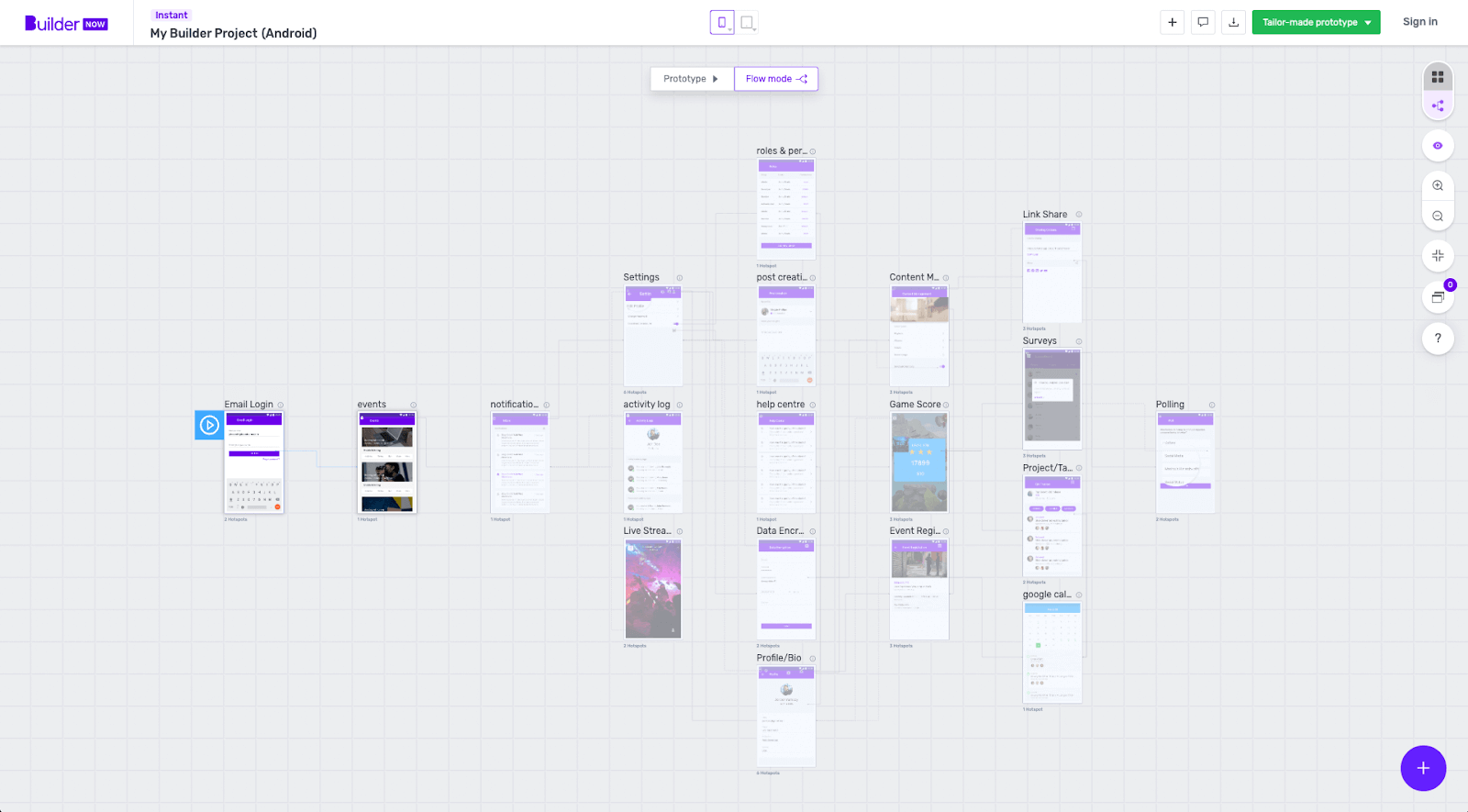
But as you can create apps with over 50 features, manually connecting all these features was extremely tedious!
Our first approach was using a preliminary set of links fetched from a curated lookup table of possible connections in our Content Management System (CMS). If your Buildcard had both Feature A and Feature B, and the link A➝B was in the CMS table, then we’d link these features in your prototype.
The problem was that this approach ignored the purpose of your app, for example, was it for ecommerce, social networking or order management? Even worse, an approach based on a lookup table didn’t always create a path from the start feature to all the other ones. This meant a significant number of links still needed to be manually added or removed.
My aim was to create a comprehensive methodology for prototype generation logic. Reducing the amount of manual labour needed to achieve a working, instant prototype – by using data we’d got from manually curated projects.
API Architecture
The chart below, shows information flow in our prototype generation API. This is how we take the information from your Buildcard and turn it into a prototype in Builder Now. I’ll talk about each of the numbered components in more detail.
- Builder Knowledge Graph
- Link prediction model
- Start Feature logic
- Postprocess
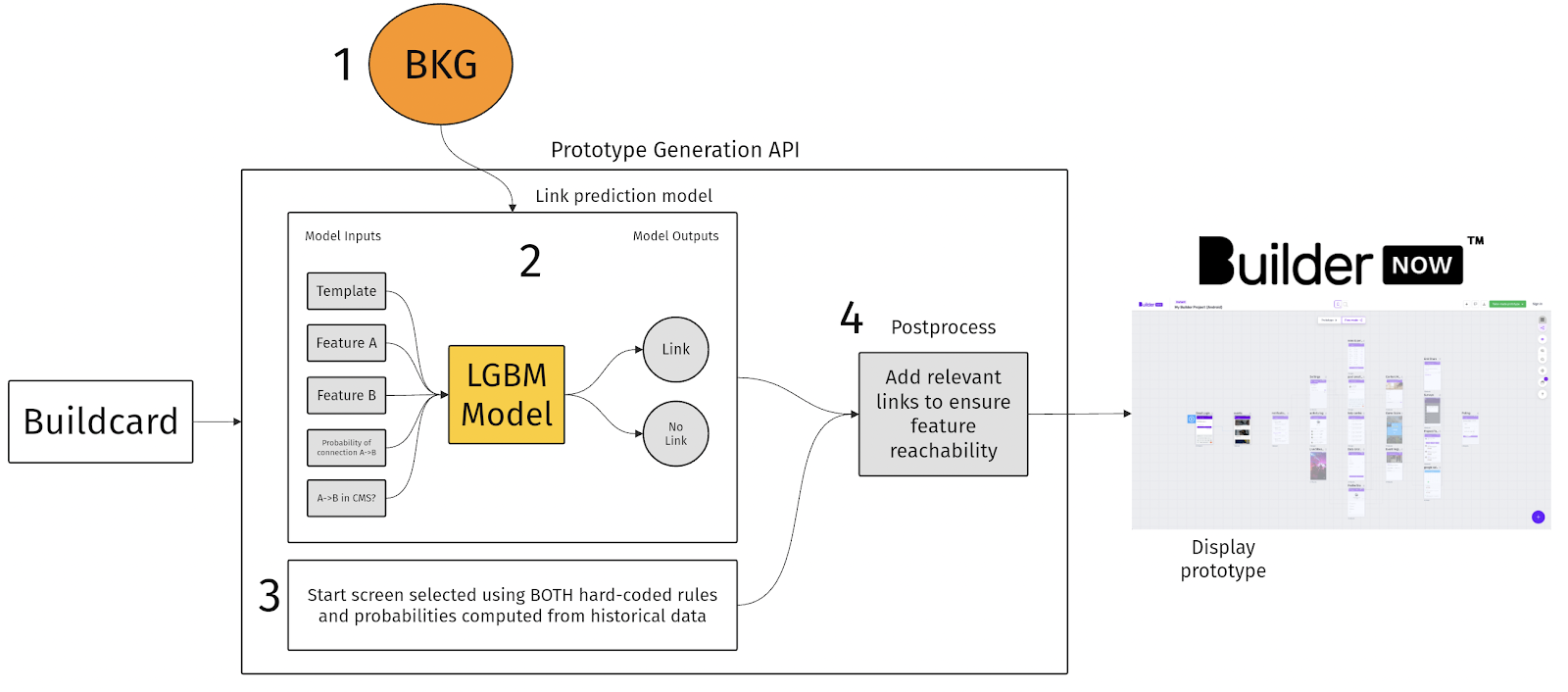
1. Builder Knowledge Graph
At Builder.ai, we think of our Builder Knowledge Graph as the brain of our operations, because it powers most of our workflows.
The graph contains the entities within our Builder.ai ecosystem (that’s everything from features, to projects and developers). And shows how all of these are connected. For example, a developer might be working on a specific feature that’s part of a bigger project.
Then we use graph embedding algorithms. They translate this information, so that it can be read and used by machine learning algorithms.
2. Link prediction model
We’ve about 1,400 historical Builder Now prototypes with approved links. The plan was to use this data to find a link prediction model.
Our model needed to predict whether any given Feature A (the source feature) should link to Feature B (the target feature).
So we compared different models using the F1 score – this is a standard metric to measure how well a model performs.
Inputs for our link prediction model
- Feature A: this input is an embedding, trained in the Builder Knowledge Graph.
- Feature B: this input is an embedding, trained in the Builder Knowledge Graph.
- Template: we get the template input by averaging the Builder Knowledge Graph embeddings associated with all the features in the template. (This gives the model some context about the other features present in the Buildcard and of the customer’s intent.)
- Probability of observing the link A ➝ B: this is precomputed using available historical data in the form of a connectivity matrix C, where the ij element is defined as:
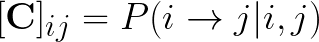
So the ij element in the connectivity matrix is the probability that there’s a link from Feature i to Feature j, given that both i and j are present in this Buildcard.
- Is A ➝ B is present in the CMS table? A binary state (0, 1)
The types of models we considered
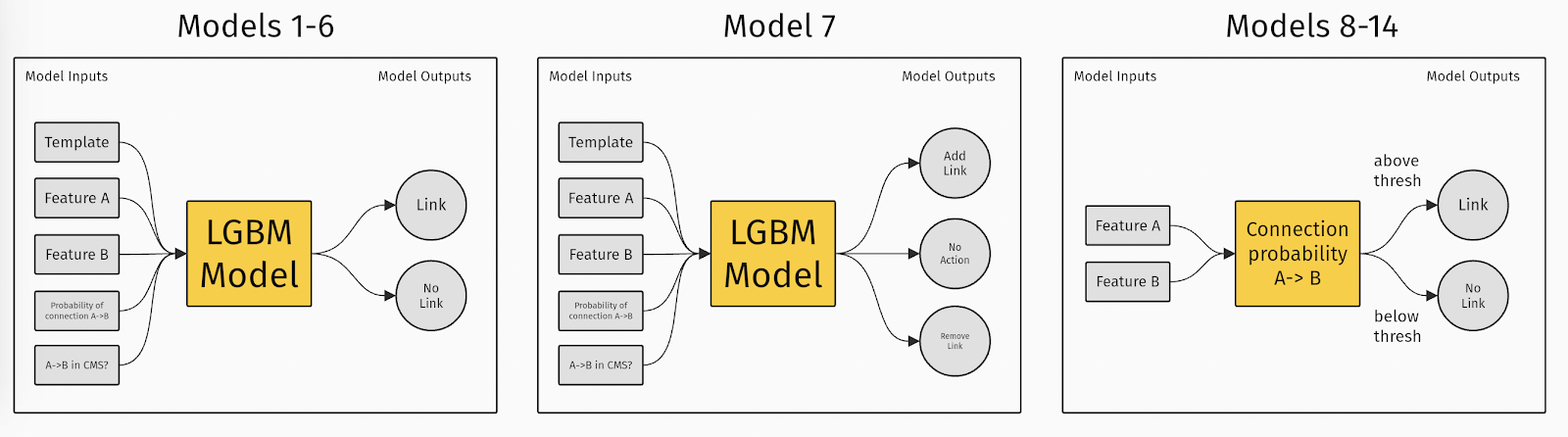
We tested 14 different models – you can group them into 3 categories:
- Models 1-6: different subsets of inputs are concatenated and fed into a Light Gradient Boosting Model (Light GBM) to get predictions in the form of a binary state, showing whether or not there should be a link between Feature A and Feature B.
- Model 7: all the available inputs are concatenated and fed into a Light GBM model to assign the feature pair to one of 3 classes: Add link, No Action, Remove Link. (These 3 actions let the model correct the links suggested by the lookup table.)
- Models 8-14: these models effectively only use Feature A and Feature B as inputs. We get the probability of connection from the precomputed Connectivity matrix. If the probability is above a cutoff threshold then a link is added to the prototype. (The value of this cutoff threshold is the only difference between 8-14.)
Selecting the best model
To compare the performance of different models we used an unseen test set of prototypes. Measuring their performance using the F1 score. (The F1 score is the harmonic mean between Precision and Recall.)
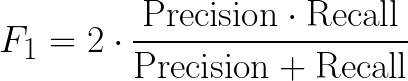
For this test, Precision and Recall mean:
- Precision: the number of correct links predicted by the model over the total number of links predicted by the model.
- Recall: the number of correct links predicted by the model, over the total number of links present in the historical prototypes.
The performance of all the models is tested in a k-fold validation fashion, which gives us a distribution of F1 scores for each model. We shortlisted model 2 and 9 and explored their outputs.
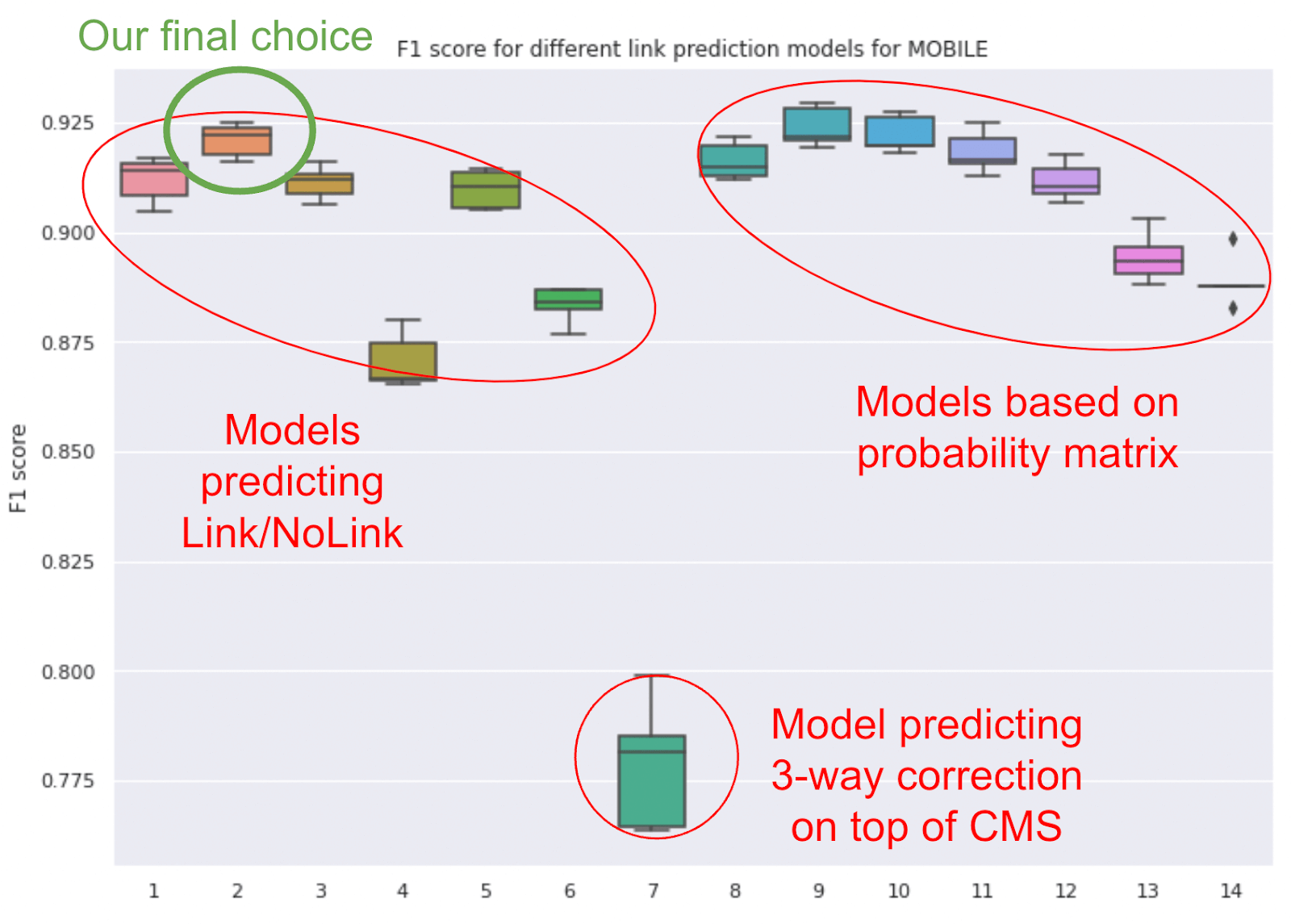
After looking at the prototypes predicted by models 2 and 9, model 9 seemed to be missing lots of relevant links. So we decided to implement model 2 in our API. This model is based on Light GBM and uses all the inputs we’ve considered in the analysis.
Its output is binary: Link vs No link.

3. Start Feature logic
How do you select the right feature to start on, from a Buildcard of unlinked features? We used a hybrid approach based on probability and heuristics. It works like this.
Each Buildcard is compared against historical prototypes – and we see which of these chosen features was most often selected as a start feature. Here are the most popular starting points in the user journey:
- Splash Screen
- Landing Page
- Sign Up
- Signup/Login Module
- Login
- Email Login
- Email Sign In
- Phone Login
- Google Login
- Facebook Login
- Twitter Login
If none of the features in your Buildcard have ever been chosen as a starting point, then we look for specific keywords in the features names – particularly, we look for the keywords “login” and “signup” to find a relevant start feature.
4. Postprocess
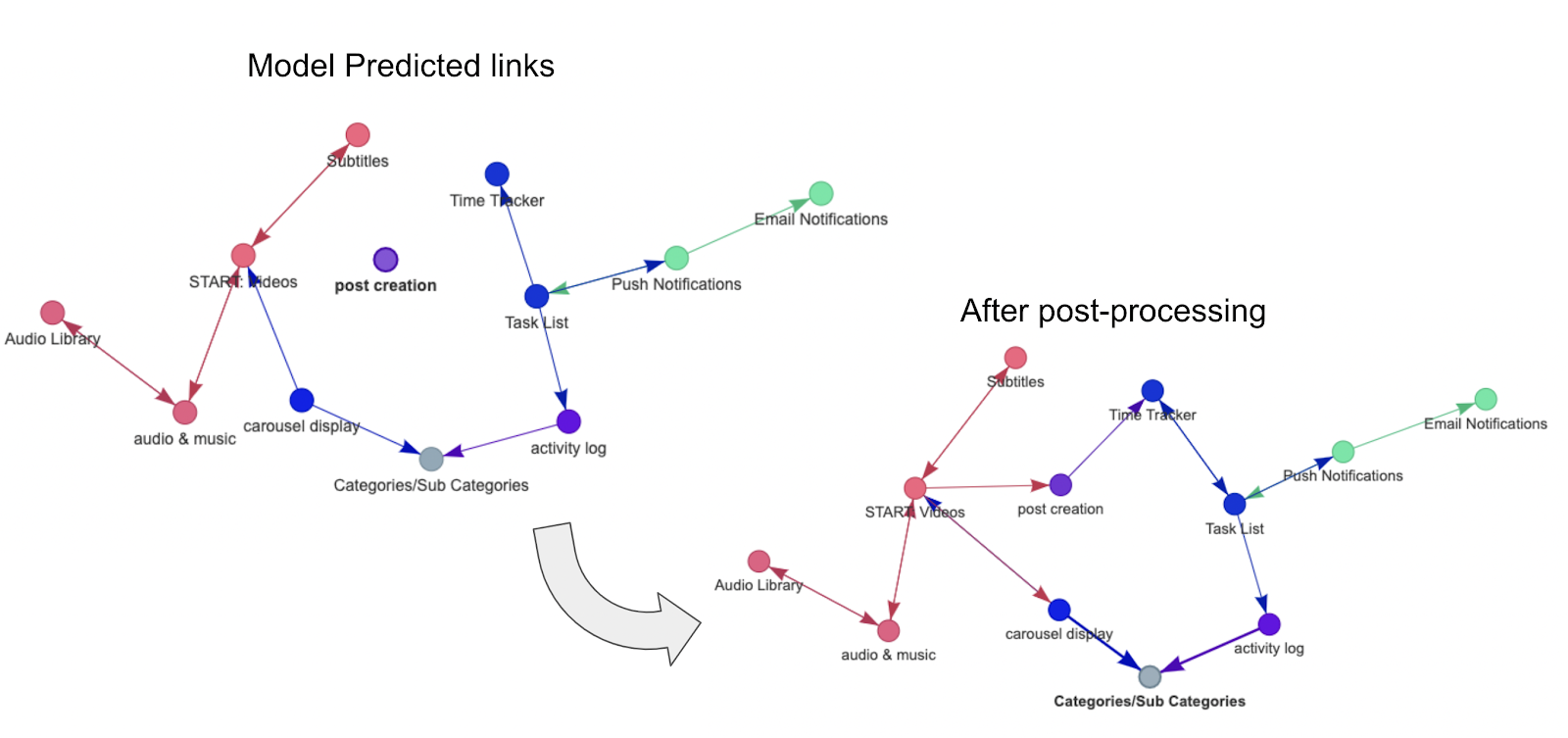
Even our best link prediction model can’t guarantee that a path exists from the start screen to any other feature in your prototype. For example, the raw output from our link prediction model could look like this:
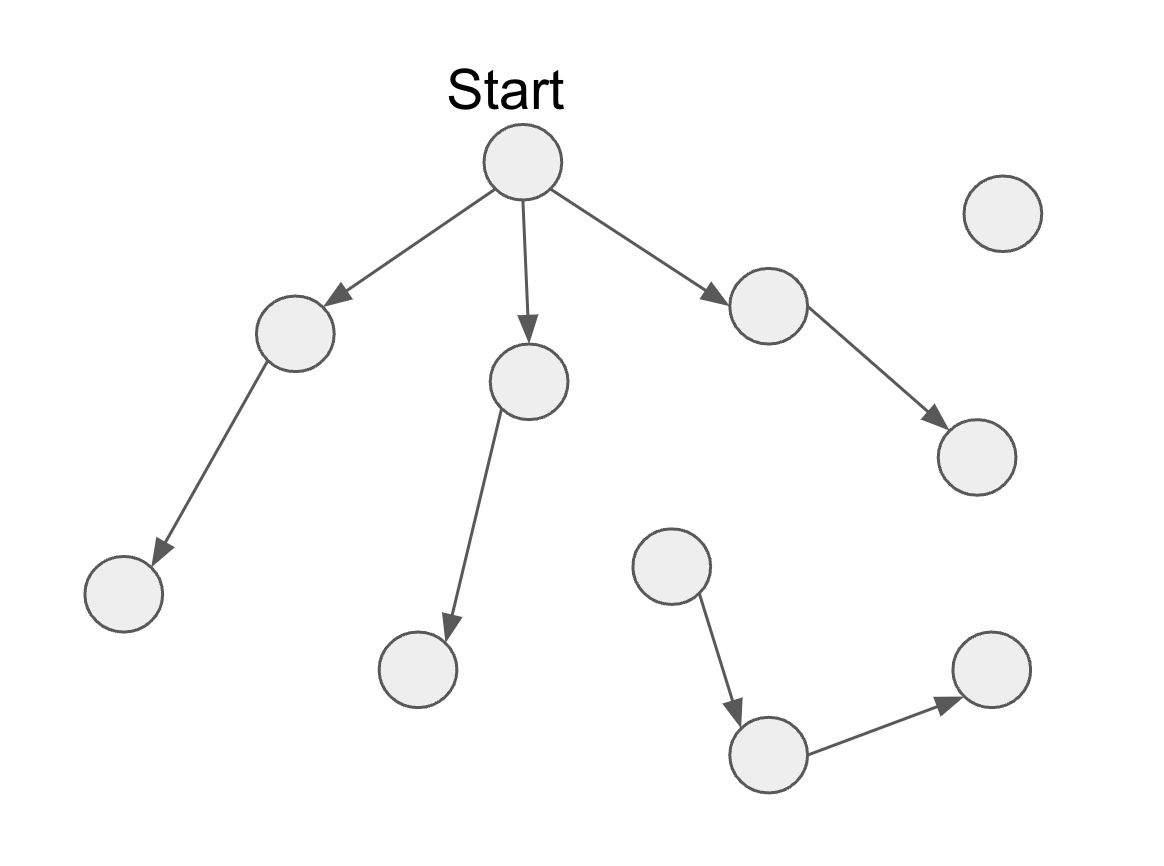
As you can see, there’s an isolated feature (top right) – as well as an isolated subgraph that you can’t get to from the start feature (bottom right).
This needs fixing. So first, the link prediction model gives us the preliminary links and selects a start feature. Then we make sure that a path exists from that start feature to any other feature in your prototype. To make sure this happens, we apply the following logic:
- Find the most relevant links to ensure all subgraphs connect to a single graph.
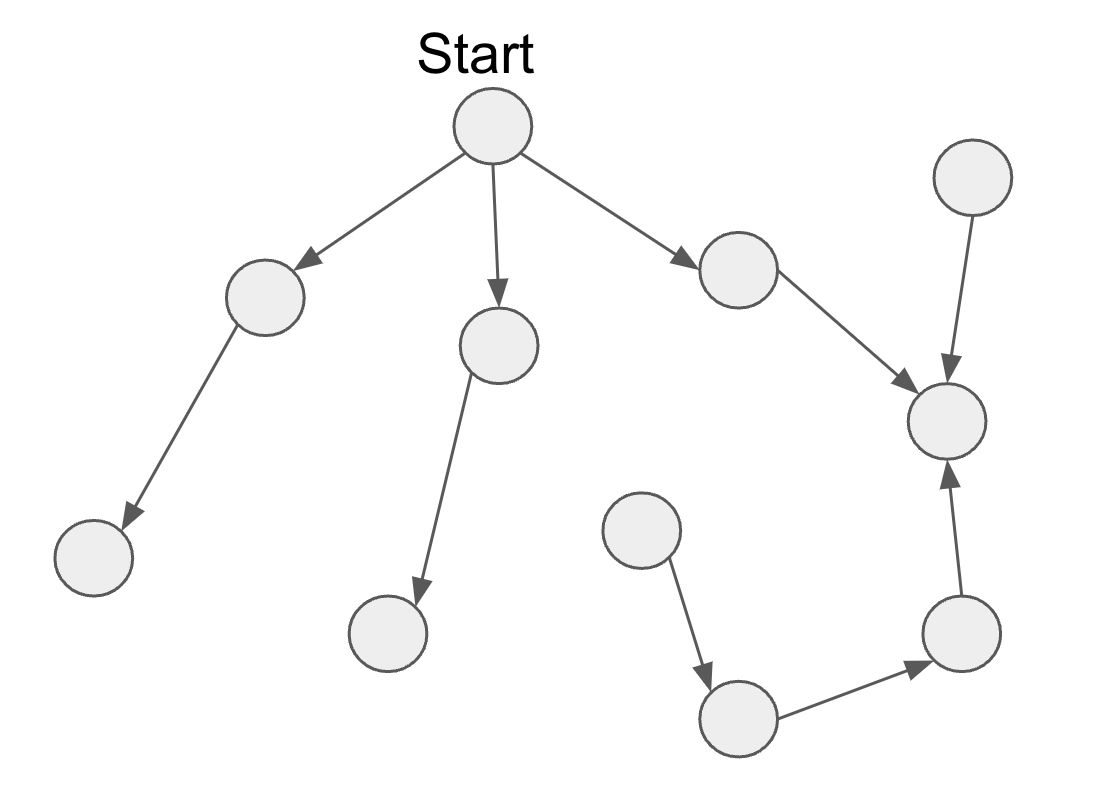
- Spot any features that can’t be reached from the start feature (in other words, all features that are not descendants of that start feature).
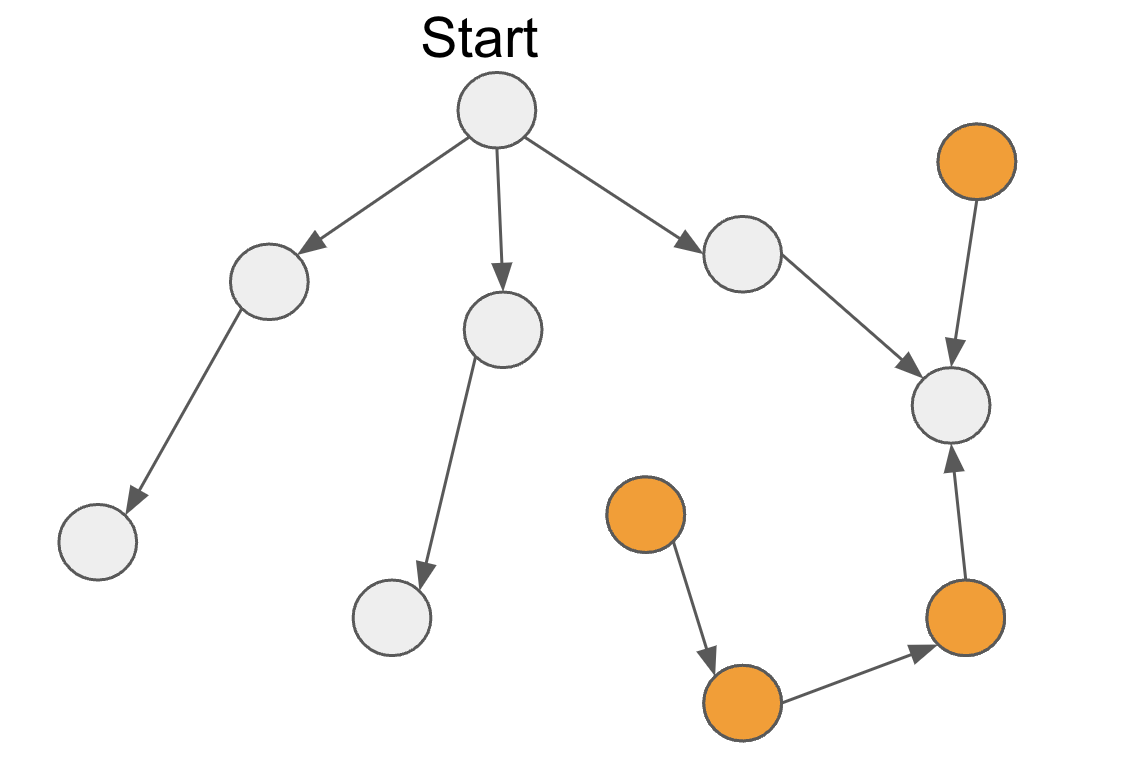
- For each of these features we find theirascendants;We then add the most relevant link between any descendant of the start feature and any ascendant of the unreachable feature. How? We find the most relevant link by finding the most probable link in the Connectivity Matrix.
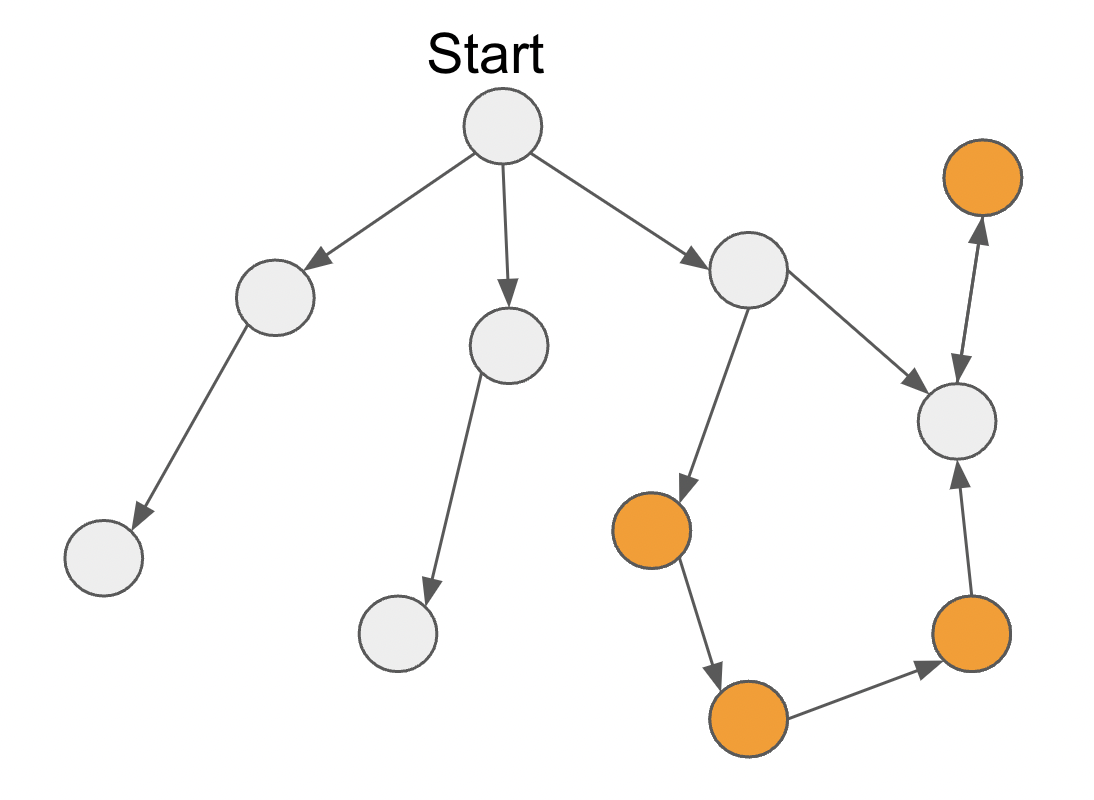
This logic makes sure all features are reachable in all the prototypes created by our API.
Results
This Machine Learning-based approach converts disconnected features from your Buildcard into an interactive prototype that you can visualise, navigate and keep developing using Builder Now.
In past versions of Builder Now, we found preliminary links by querying a list of possible connections from a lookup table. Our new approach improves the user experience by providing more relevant feature connections and reducing the amount of manual labour needed to add or remove links to fix the user journey.
We asked product experts to validate the output produced by our prototype generation model on a number of sample projects, to quantify the change in performance. We also got time estimates, validated with product managers, for manually approving a link, adding a link or removing a link in the prototype.
From this validation exercise, we estimate that preliminary prototypes returned by our API – have reduced prototype design time by between 25% and 85%.
I am a quantitative researcher with a profound interest and substantial experience on intelligent algorithms for system identification. I am currently employed at Builder.ai as a Data Scientist in the Intelligent Systems team, where I am working on solutions towards the automation of the software development cycle. My technical expertise covers Maximum Likelihood inference, Model-Based Design of Experiments, Machine Learning, online model identification, process-model mismatch diagnosis and solution of ill-posed model identification problems.





 Facebook
Facebook X
X LinkedIn
LinkedIn YouTube
YouTube Instagram
Instagram RSS
RSS

